故障率
故障率(こしょうりつ、英: failure rate)とは、システムや部品が故障する頻度で、単位時間当たりの故障数で表される。通常、ギリシア文字の λ(ラムダ)で表され、信頼性工学でよく用いられる。
故障率は通常、時間に依存している。例えば、自動車の5年目の故障率は1年目のそれの何倍にもなる可能性がある。
保険、金融、商業においても安全なシステムを設計するための基本的なパラメータである。
1年間の使用でシステムや部品が故障する確率を特に「年間故障率」と表現することがある。
平均故障間隔
「平均故障間隔」も参照
故障率の代わりに平均故障間隔(MTBF、1/λ)が報告されることがよくある。MTBFは、故障率が一定の場合に有効であり、複雑なシステムや電子機器によく用いられる。一部の信頼性基準(軍事および航空宇宙)では一般的となっている。故障率が一定ということは、バスタブ曲線の平坦な領域、つまり摩耗型の故障が起こる前の時間領域での寿命を示す。このため、MTBFから耐用年数を推定することは正しくない。バスタブ曲線の「寿命末期の磨耗型」の故障率ははるかに高いため、一般的に耐用年数はMTBFよりもはるかに短寿命になるためである。
MTBFが故障率より好まれる理由は、大きな正の数値(2000時間など)の方が、非常に小さな数値(1時間あたり0.0005など)よりも直感的で覚えやすいためである。
MTBFは故障率を管理する必要があるシステム、特に安全系において重要なパラメータである。設計要件に頻繁に登場し、必要なシステムの保守・点検の頻度を定めるのに役立つ。故障からの回復時間が無視でき、かつ故障率が時間に対して一定である場合、MTBFは故障率の逆数(1/λ)になる。
運輸業界、特に鉄道やトラック輸送で使われている類似の指標に「平均故障距離間隔」(mean distance between failures、MDBF)がある。
故障率の推定
故障率はいくつかの方法で推定できる。故障時間の母集団を正しく推定できれば良い。一般的な手段は次のとおりである。
寿命試験
最も正確な方法は寿命試験(life testing)であり、機器やシステムのサンプルをテストして実際の故障データを得る。故障時間が全くばらつかない場合、1サンプルのみを試験すれば良いが、現実には個体毎にばらつく場合が多い。このばらつきを把握する(故障時間の母集団を推定する)ため、サンプル規模は大きくながちで非常に費用がかかる。また、故障時間が非常に長い場合、現実的な時間で試験を終了させることも困難になる。
市場実績
市場で実際に発生した故障データから、統計分析で故障率を推定することができる。正確な故障率を得るためには、分析者は機器の動作、データ収集の手順、故障率に影響を与える主要な環境変数、システムレベルでの機器、部品の使用方法などを十分に理解している必要がある。
生産履歴
多くの組織では、製造している機器やシステムの故障情報を内部データベースとして保持しており、故障率を算出するために使用することができる。新しい機器やシステムでデータが少ない場合には、過去のデータが有用な事前情報として役立つ。
政府および商用の故障率データ
さまざまな部品の故障率のハンドブックが政府や民間から入手できる。「電子機器の信頼度予測(Reliability Prediction of Electronic Equipment)」(MIL-HDBK-217F)は、多くの軍用電子部品の故障率データを提供する軍用規格である。また、非電子部品を含む商用部品に焦点を当てたいくつかの故障率データソースが市販されている。
予測法
故障率推定の重大な欠点の1つに時間がかかることがある。故障率データが集まる頃には、対象となる機器が旧式になっていることがよくある。これを克服するために以下のサイクル試験などが故障率予測法として開発されている。
サイクル試験
機械的な動作は機器の摩耗を引き起こし、主な故障メカニズムとなる。この消耗故障点は、サイクル試験(cycle testing)により、機器が故障するまでに実行されたサイクル数で定量化される。サイクル試験は機器が故障するまで可能な限り迅速に繰り返される。複数のサンプルを試験し、例えばその内の10%の個体が故障するまで試験が行われる。
離散的な故障率
故障率は次のように定義される:
規定の条件下における特定の測定間隔の間に、あるアイテムの母集団内で起こった故障総数を、その集団が費やした合計時間で割ったもの。(MacDiarmid, et al.)
故障率 は、しばしば時間 以前に故障がない場合に特定の間隔で故障が発生する確率と考えられがちだが、1を超えることもあるので実際には確率ではない。故障率を誤ってパーセント(%)で表現すると、特に修理可能なシステム、故障率一定型でないシステム、または動作時間が異なる複数のシステムについて測定する場合に、この尺度を正しく認識できない可能性がある。故障率 は、信頼性関数 (時刻 以前に故障が発生しない確率。生存関数とも呼ばれる)を用いて次のように定義される。



- ,

ここに は(最初の)故障までの時間分布(すなわち故障密度関数)である。(または )から までの時間区間 = において、






ただし、これは条件付き確率であり、時間 以前に故障が発生していないことが条件である。そのため、分母には が含まれている。

ハザード率(後述)とROCOF(rate of occurrence of failures、故障発生率)は、しばしば故障率と同じものと誤解されることがある[要説明]。違いを明確にするならば、アイテムの修理が早ければ早いほど、またすぐに壊れるので、ROCOFは高くなる。しかし、ハザード率は、修復時間や物流遅延時間には依存しない。
連続的な故障率
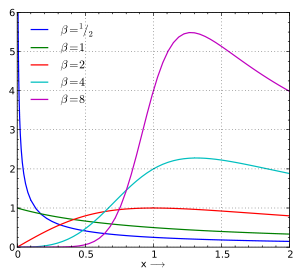

故障率をより小さな時間間隔で計算すると、ハザード関数(hazard function、ハザード率(hazard rate)とも呼ばれる) が得られる。これは、 がゼロに近づくにつれて、瞬間故障率(instantaneous failure rate)あるいは瞬間ハザード率(instantaneous hazard rate)と呼ばれるものになる。

連続故障率は、時刻 まで(少なくとも)の故障確率 を表す累積分布型の故障分布関数 に依存しており、



と表される。ここに は故障時間である。

この故障分布関数は、故障密度関数 の積分で、

である。これによりハザード関数は、

と定義できる。

故障分布のモデル化においては、多くの確率分布を用いることができる(確率分布のリスト(英語版)を参照)。
一般的なモデルは、指数密度関数に基づく指数故障分布、

である。
これに対するハザード率関数は、

である。このように、指数故障分布では、ハザード率は時間に対して一定である(つまり「無記憶性(英語版)」分布)。ワイブル分布や対数正規分布のような他の分布では、ハザード関数は時間に対して一定ではない場合がある。確定的分布などの一部では単調増加であり(「摩耗」に類似)、パレート分布などの他の分布では単調減少であるが(「バーンイン(英語版)」に類似)、多くの場合は単調ではない。
微分方程式

を について解くと、

であることがわかる。
故障率減少型
詳細は「故障率曲線」を参照
故障率減少型(decreasing failure rate、DFR)とは、ある事象が将来の一定の時間間隔で発生する確率が、時間の経過とともに減少していく現象を表す。故障率減少型は、初期に起こる故障が解消または修正される「初期故障期間」を表すことができ[1]、λ(t) が減少関数である状況に対応する。
DFR変数の混合はDFRである[2]。指数分布確率変数の混合は、超指数分布(英語版)である。
再生過程
DFR再生関数を持った再生過程(英語版)(renewal processes)では、再生間時間は凹になる[2][3][訳語疑問点]。Brownは逆に、再生間時間が凹になるためにはDFRが必要であると推測したが[4]、この推測は離散的な場合[3]にも連続的な場合にも成り立たないことが示されている[5]。
用途
故障率増加型(Increasing failure rate、IFR)は、部品が消耗することによって起こる直感的な概念である。故障率減少型(DFR)は、経年変化によって改善されるシステムを表す[6]。宇宙船の寿命においても故障率減少型が見られ、Baker and Bakerは『最後に残ったこれらの宇宙船は、延々と続く。』("These spacecraft that last, last on and on.")とコメントしている[7][8]。航空機の空調システムの信頼性は、個々に指数分布を持つことが分かっており、プールされた母集団ではDFRとなる[6]。
変動係数
故障率が減少している場合、変動係数 ⩾ 1 であり、故障率が増加している場合、変動係数 ⩽ 1 である[9]。この結果は、すべての t ⩾ 0 [10]に対して故障率が定義されている場合にのみ成立し、逆の結果(変動係数が故障率の性質を決める)は成立しない。
単位
故障率は任意の時間の尺度で表すことができるが、実際には時間(hours)が最も一般的な単位である。時間の代わりに、マイルや回転数などの他の単位を使用することもできる。
故障率は非常に低いことが多いため、特に個々の部品の故障では、100万個あたりの故障数または工学表記(英語版)(10-6)で表されることがよくある。
デバイスの故障率(Failures In Time、FIT)は、10億(109)デバイス時間の動作で予想される故障の数である[11]。たとえば、1000個のデバイスで100万時間や、100万個のデバイスで1000時間など、さまざまな組み合わせが考えられる。この用語は、特に半導体業界で使用されている。
FITとMTBFの関係は次のように表される。
- MTBF = 1,000,000,000 × 1/FIT
加法性
ある種の工学的な仮定(たとえば、故障率一定型に関する上記の仮定に加えて、考慮されるシステムには関連する冗長性がないという仮定)の下では、複雑なシステムの故障率は、単位が一貫している限り、その構成要素の個々の故障率の単純な合計となる(たとえば、100万時間当たりの故障数)。これにより、個々の構成要素またはサブシステムをテストすることが可能になり、それらの故障率を加算してシステム全体の故障率を得ることができる[12][13]。
単一故障点をなくすために「冗長」部品を追加すると、ミッション故障率は改善するが、直列故障率(ロジスティクス故障率とも呼ばれる)は悪化する。つまり、追加の部品は平均重大故障間隔(mean time between critical failures、MTBCF)を改善させる反面、何かが故障するまでの平均時間は悪化する[14]。
計算例
特定の部品の故障率を推定する必要があると仮定する。その故障率を推定するために、テストを行うことができる。同一の部品10個は、それぞれが故障するか1000時間に達するまでテストされ、その時点でその部品のテストを終了する。(この例では、統計的な信頼区間は考慮されていない)。その結果は次のとおりである。
推定故障率は、

となり、100万時間稼働するごとに799.8件の故障が発生する。
参照項目

ポータル 数学
脚注
- ^ Finkelstein, Maxim (2008). “Introduction”. Failure Rate Modelling for Reliability and Risk. Springer Series in Reliability Engineering. pp. 1–84. doi:10.1007/978-1-84800-986-8_1. ISBN 978-1-84800-985-1
- ^ a b Brown, M. (1980). “Bounds, Inequalities, and Monotonicity Properties for Some Specialized Renewal Processes”. The Annals of Probability 8 (2): 227–240. doi:10.1214/aop/1176994773. JSTOR 2243267.
- ^ a b Shanthikumar, J. G. (1988). “DFR Property of First-Passage Times and its Preservation Under Geometric Compounding”. The Annals of Probability 16 (1): 397–406. doi:10.1214/aop/1176991910. JSTOR 2243910.
- ^ Brown, M. (1981). “Further Monotonicity Properties for Specialized Renewal Processes”. The Annals of Probability 9 (5): 891–895. doi:10.1214/aop/1176994317. JSTOR 2243747.
- ^ Yu, Y. (2011). “Concave renewal functions do not imply DFR interrenewal times”. Journal of Applied Probability 48 (2): 583–588. arXiv:1009.2463. doi:10.1239/jap/1308662647.
- ^ a b Proschan, F. (1963). “Theoretical Explanation of Observed Decreasing Failure Rate”. Technometrics 5 (3): 375–383. doi:10.1080/00401706.1963.10490105. JSTOR 1266340.
- ^ Baker, J. C.; Baker, G. A. S. . (1980). “Impact of the space environment on spacecraft lifetimes”. Journal of Spacecraft and Rockets 17 (5): 479. Bibcode: 1980JSpRo..17..479B. doi:10.2514/3.28040.
- ^ Saleh, Joseph Homer; Castet, Jean-François (2011). “On Time, Reliability, and Spacecraft”. Spacecraft Reliability and Multi-State Failures. pp. 1. doi:10.1002/9781119994077.ch1. ISBN 9781119994077
- ^ Wierman, A.; Bansal, N.; Harchol-Balter, M. (2004). “A note on comparing response times in the M/GI/1/FB and M/GI/1/PS queues”. Operations Research Letters 32: 73–76. doi:10.1016/S0167-6377(03)00061-0. http://users.cms.caltech.edu/~adamw/papers/fbnote.pdf.
- ^ Gautam, Natarajan (2012). Analysis of Queues: Methods and Applications. CRC Press. p. 703. ISBN 978-1439806586
- ^ Xin Li; Michael C. Huang; Kai Shen; Lingkun Chu. "A Realistic Evaluation of Memory Hardware Errors and Software System Susceptibility". 2010. p. 6.
- ^ "Reliability Basics". 2010.
- ^ Vita Faraci. "Calculating Failure Rates of Series/Parallel Networks". 2006.
- ^ "Mission Reliability and Logistics Reliability: A Design Paradox".
推薦文献
- Goble, William M. (2018), Safety Instrumented System Design: Techniques and Design Verification, Research Triangle Park, NC 27709: International Society of Automation
- Blanchard, Benjamin S. (1992). Logistics Engineering and Management (Fourth ed.). Englewood Cliffs, New Jersey: Prentice-Hall. pp. 26–32. ISBN 0135241170
- Ebeling, Charles E. (1997). An Introduction to Reliability and Maintainability Engineering. Boston: McGraw-Hill. pp. 23–32. ISBN 0070188521
- Federal Standard 1037C
- Kapur, K. C.; Lamberson, L. R. (1977). Reliability in Engineering Design. New York: John Wiley & Sons. pp. 8–30. ISBN 0471511919
- Knowles, D. I. (1995). “Should We Move Away From 'Acceptable Failure Rate'?”. Communications in Reliability Maintainability and Supportability (International RMS Committee, USA) 2 (1): 23.
- MacDiarmid, Preston; Morris, Seymour (n.d.). Reliability Toolkit (Commercial Practices ed.). Rome, New York: Reliability Analysis Center and Rome Laboratory. pp. 35–39
- Modarres, M.; Kaminskiy, M.; Krivtsov, V. (2010). Reliability Engineering and Risk Analysis: A Practical Guide (2nd ed.). CRC Press. ISBN 9780849392474
- Mondro, Mitchell J. (June 2002). “Approximation of Mean Time Between Failure When a System has Periodic Maintenance”. IEEE Transactions on Reliability 51 (2): 166–167. doi:10.1109/TR.2002.1011521. http://www.mitre.org/work/best_papers/02/mondro_approx/mondro_approx.pdf.
- Rausand, M.; Hoyland, A. (2004). System Reliability Theory; Models, Statistical methods, and Applications. New York: John Wiley & Sons. ISBN 047147133X
- Turner, T.; Hockley, C.; Burdaky, R. (1997). The Customer Needs A Maintenance-Free Operating Period. Leatherhead, Surrey, UK: ERA Technology Ltd.
- U.S. Department of Defense, (1991) Military Handbook, “Reliability Prediction of Electronic Equipment, MIL-HDBK-217F, 2
外部リンク
- Bathtub curve issues, ASQC
- Fault Tolerant Computing in Industrial Automation by Hubert Kirrmann, ABB Research Center, Switzerland
| |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 標本調査 | |||||||||||||||
| 要約統計量 |
| ||||||||||||||
| 推計統計学 |
| ||||||||||||||
| ベイズ統計学 |
| ||||||||||||||
| 相関 |
| ||||||||||||||
| モデル | |||||||||||||||
| 回帰 |
| ||||||||||||||
| 分類 |
| ||||||||||||||
| 教師なし学習 |
| ||||||||||||||
| 統計図表 | |||||||||||||||
| 生存分析 | |||||||||||||||
| 歴史 |
| ||||||||||||||
| 応用 | |||||||||||||||
| 出版物 |
| ||||||||||||||
| 全般 | |||||||||||||||
| その他 | |||||||||||||||
| | |||||||||||||||








