Model Booleà Estès

El Model Booleà Estès és una variació del Model Booleà, que permet un maneig més flexible dels termes de la consulta i una revisió dels resultats. El Model Booleà Estès va ser presentat en un article de Communications of the ACM en l'any 1983, per Gerard Salton, Edward A. Fox i Harry Wu, amb el propòsit superar els desavantatges del Model Booleà que ha estat utilitzat en recuperació d'informació.
El Model Booleà no considera els pesos dels termes en les consultes i el conjunt resposta d'una consulta booleana és sovint massa petita o massa gran. La sol·licitud de recuperació booleana clàssica determina quins elements han d'aparèixer en els resultats de la consulta. La sol·licitud divideix els documents en dos grups: aquells documents no compleixen amb la sol·licitud i els que la compleixen. Això porta dos problemes:
- Un document que no conté un terme requerit no es troba. No obstant això, el document podria ser rellevant. Potser el terme requerit simplement apareix amb un nom diferent (sinonímia). Altres termes de consulta poden ser nombrosos.
- Els documents que coincideixen amb els criteris de la consulta, no poden ser ordenats per rellevància.
La idea del model estès és fer ús de la correspondència parcial i els pesos dels termes del Model d'Espai Vectorial, combinant-los amb les propietats de l'àlgebra booleana, intentant abordar aquests problemes amb la naturalesa binària del àlgebra booleana (veritat - fals); els valors es defineixen matemàticament en un interval [0,1], amb 0 és «fals» i 1 és «veritat». D'aquesta manera, un document pot ser una mica rellevant si conté alguns termes de la consulta i pot ser obtingut com a resposta, mentre que en el Model Booleà això no passa.[1]
Així, el Model Booleà Estès pot ser considerat com una generalització dels models booleà i vectorial. A més, la investigació ha demostrat millores en l'efectivitat respecte al processament de consultes del model booleà. Altres investigacions han mostrat que la retroalimentació i l'expansió de consultes poden ser adaptades al processament de consultes del Model Booleà Estès.
Definicions
En el Model Booleà Estès, un document es representa per un vector, la 4-tupla (T , Q , D , rang (.,.)), igual que en el Model Vectorial. Cada component correspon a un terme associat al document:
- T = { ti | i = 1, ..., n}: conjunt d'índex de termes, documents i descripcions de consultes.
- Q = { qj | i = 1, ...}: conjunt de totes les consultes permeses.
- D = { dk | k = 1, ..., m}: quantitat d'aquest document. En els models booleanes estesos cada terme té tki d'un document dk un pes wki ∈ [0,1], representant la importància del terme en el document. D'aquesta manera, un document dk té l'estructura dk = (( tk1 , wk1 ), ..., ( tkN , wkn )).
- rang (..): funció de la classificació, que descriu la similitud d'un document amb una consulta. En general, es defineix per: rang (dk , qj): D x Q → [0,1]: (dk , qj | → rang (dk, qj) ∈ [0,1].
En la funció de classificació es descriuen les diferents classes del Model Booleà Estès; en tots els models es poden distingir els operadors lògics AND i OR en la consulta.
El pes del terme associat al document es mesura per la seva freqüència de terme normalitzada i pot definir-se com:



on és la freqüència inversa de document.

El vector de pesos associat al document pot ser representat com:
![{\displaystyle \mathbf {v} _{d_{j}}=[w_{1,j},w_{2,j},\ldots ,w_{i,j}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7630d41a2858849a4a1998c1a7bf46c90a18d7cc)
Exemple en 2 dimensions
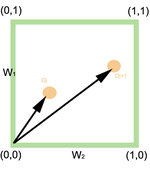




Considerant l'espai compost pels dos termes y , els pesos corresponents són i .[2] Així, per a la consulta, podem calcular la similitud amb la següent fórmula:





Per a la consulta , podem fer servir:


Generalització de la idea
Podem generalitzar l'exemple anterior en 2 dimensions del Model Booleà Estès a l'espai t-dimensional usant la distància Euclidiana.
Això pot fer-se usant Norma-P, que estén la noció de distància per incloure p-distàncies, on és un nou paràmetre.

- Una consulta conjuntiva general està donada per:

La similitud de la consulta i el document pot definir-se com:

![{\displaystyle sim(q_{or},d_{j})={\sqrt[{p}]{\frac {w_{1}^{p}+w_{2}^{p}+....+w_{t}^{p}}{t}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4ee6fd28a0b708483aa6ff23a382886234751498)
- Una consulta disjuntiva general està donada per:

La similitud de la consulta i el document pot definir-se com:

![{\displaystyle sim(q_{and},d_{j})=1-{\sqrt[{p}]{\frac {(1-w_{1})^{p}+(1-w_{2})^{p}+....+(1-w_{t})^{p}}{t}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e8a46594acad810a7ec2e9e62a712b694fb18916)
Exemples
Penseu en la consulta . La similitud entre la consulta i el document pot calcular-se usant la fórmula:



![{\displaystyle sim(q,d)={\sqrt[{p}]{\frac {(1-{\sqrt[{p}]{({\frac {(1-w_{1})^{p}+(1-w_{2})^{p}}{2}}}}))^{p}+w_{3}^{p}}{2}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/74b3d2b11ee65d16df85d7d45087259d37a10215)
Models booleans avançats sense pesos de consulta
En aquesta classe de models cada consulta es representa com una combinació dels termes d'índex i els operadors lògics AND, OR, NOT, entre la possible utilització de qualsevol expressió entre parèntesis. Es creu que tots els termes tenen el mateix significat, que està representat per la falta de pesos termini en la consulta. Els següents models booleans estesos es poden distingir:
Model de conjunts difusos simples (Buell 1981, Bookstein 1980, Radecki 1979)
- rang (dk, t1 AND t₂) = MIN {wk1, wk2}
- rang (dk, t1 OR t₂) = MAX {wk1, wk2}
Aquest model simple té la limitació que només es pot avaluar dos termes, en contraposició als següents models que poden gestionar molts termes arbitraris.
Model Waller-Kraft (Waller i Kraft 1979)
- rang (dk, t1 AND ... AND tn) = (1 - γ) · MIN {wk1, ..., wkn} + γ · MAX {wk1, ..., wkn}, 0 ≤ γ ≤ 0,5
- rang (dk, t1 OR ... OR tn) = (1 - γ) · MIN {wk1, ..., wkn} + γ · MAX {wk1, ..., wkn}, 0,5 ≤ γ ≤ 1
Model Paice (Paice 1984)
En una operació inicial AND s'organitza els pesos wki en valors creixents, és a dir, wk1 ≤ ... ≤ wkN, i després es calcula
- rang (dk, t1 AND ... AND tn) = (∑i=1n (ri-1 · wki)) / (∑i=1n ri-1), 0 ≤ r ≤ 1
En una operació inicial OR s'organitza els pesos wki en valors descendent, és a dir, wk1 ≥ ... ≥ wkN, i després es calcula
- rang (dk, t1 OR ... OR tn) = (∑i=1n (ri-1 · wki)) / (∑i =1n ri-1), 0 ≤ r ≤ 1
Podel P-estàndard (Salton et al., 1983)
- rang (dk, t1 AND ... AND tn) = 1 - (1 / n · ∑i=1n (1 - wki)p)1/p, 1 ≤ p <∞
- rang (dk, t1 OR ... OR tn) = 1 - (1 / n · ∑i=1n (wki)p)1/p, 1 ≤ p <∞
Model infinit i un (Smith 1990)
- rang (dk, t1 AND ... AND tn) = γ · (1 - MAX {1 - wk1, ..., 1 - wkn}) + (1 - γ) · (1 / n · ∑i=1n wki), 0 ≤ γ ≤ 1
- rang (dk, t1 OR ... OR tn) = γ · MAX {wk1, ..., wkn} + (1 - γ) · (1 / n · ∑i=1n wki), 0 ≤ γ ≤ 1
Els models booleans avançats amb pesos de consulta
L'efectivitat de la recuperació es pot augmentar per factors d'importància que s'assignen als termes en forma de pesos. Una consulta qj d'aquesta manera crea una estructura anàloga a un document dk amb tuples de termes i pesos. Són termes que no es produeixen en la consulta d'origen que codifica un pes zero, pel que cada consulta d'origen es poden codificar en una consulta que tingui en compte tots els termes que apareixen en T:
- qj = ((tq(j)1, wq(j)1), ..., (tq(j)n, wq(j)n)).
Els enfocaments rellevants de ponderació (veure Buell (1981)), reformulen les funcions de classificació tal que els pesos dels documents i les consultes es multipliquen, és a dir:
- rang (dk, (tq(j), wq(j))) = wk · wq(j)
Sota aquest supòsit, moltes de les funcions del Model Booleà Estès P-estàndard i del Model Booleà Estès infinit i un són capaces d'avaluar els pesos en els documents i una consulta:
Model P-estàndard amb pesos de consulta
- rang (dk (tq(j)1, wq(j)1) AND ... AND (tq(j)n, wq(j)n)) = 1 - ((∑i=1n (1 - wki)p · wq(j)ip) / (∑i=1n wkip))1/p, 1 ≤ p <∞
- rang (dk (tq(j)1, wq(j)1) OR ... OR (tq(j)n, wq(j)n)) = 1 - ((∑i=1n wkip · wq(j)ip) / (∑i=1n wkip))1/p, 1 ≤ p <∞
Model infinit i un amb pesos de consulta
- rang (dk, (tq(j)1, wq(j)1) AND ... AND (tq(j)n, wq(j)n)) = γ · (1 - ((MAX {(1 - wk1) · wq(j)1, ..., (1 - wkn) · wq(j)n}) / (MAX {wq(j)1, ..., wq(j)n})) + (1 - γ) · ((∑i=1n (wki · wq(j)i) / (∑i=1n wq(j)i)), 0 ≤ γ ≤ 1
- rang (dk, (tq(j)1, wq(j)1) OR ... OR (tq(j)n, wq(j)n)) = γ · (MAX {wk1 · wq(j)1, ..., wkn · wq(j)n}) / (MAX {wq(j)1, ..., wq(j)n}) + (1 - γ) · ((∑i=1n (wki · wq(j)i) / (∑i=1n wq(j)i)), 0 ≤ γ ≤ 1
Millores respecte al Model Booleà
Lee i Fox[3] van comparar els models Booleà i Booleà Estès amb tres col·leccions de prova: CISI, CACM i INSPEC.
Utilitzant Norma-P es va obtenir una mitjana de millores en la precisió de 79%, 106% i 210% respecte al Model Booleà estàndard, per a les col·leccions CISI, CACM i INSPEC, respectivament.
El model de Norma-P és computacionalment costós pel nombre d'operacions d'exponenciació que requereix; però, aconsegueix resultats molt millors que el Model Booleà, i fins i tot que el Model Fuzzy. El Model Booleà estàndard és, però, el més eficient.
Referències
- ↑ Salton, Gerard; Fox, Edward A.; Wu, Harry «Extended Boolean information retrieval» (en anglès). Communications of the ACM, 1983.
- ↑ «Lusheng Wang». Arxivat de l'original el 2012-02-22. [Consulta: 29 juliol 2017].
- ↑ Lee, W. C.; Fox, E. A.. Experimental Comparison of Schemes for Interpreting Boolean Queries (en anglès), 1988.
Bibliografia
- Buell, D.A.: A general model for query processing in information retrieval system. In: Information Processing and Management, 17, 1981, S. 249–262.
- Bookstein, A.: Fuzzy requests: an approach to weighted boolean searches. In: Journal of the American Society for Information Science, 31, 1980, S. 240–247.
- Fox, E.A.; Betrabet, S.; Koushik, M.; Lee, W.: Extended boolean models. In: Frankes, W.B.; Yates, R.B. (eds): Information Retrieval Data Structures and Algorithms. Prentice Hall, 1992, S. 393–418.
- Kim, M.H.; Lee, J.H.; Lee, Y.J.: Analysis of fuzzy operators for high quality information retrieval. In: Information Processing Letters, 46 (5), 1993, S. 251–256.
- Lee, J.H.; Kim, M.H.; Lee, Y.J.: Ranking documents in thesaurus-based boolean retrieval systems. In: Information Processing and Management, 30, 1994, S. 79–91.
- Lee, J.H.; Kim, M.I.I.; Lee, Y.J.: Enhancing the fuzzy set model for high quality document rankings. In: Proceedings of the 19th Euromicro Conference.1992, S. 337–344.
- Lee, J.H.; Kim, W.Y.; Kim, M.H.; Lee, Y.J.: On the evaluation of boolean operators in the extended boolean retrieval framework. In: SIGIR 1993, 1993, S. 291–297.
- Lee, Joon Ho: Properties of extended Boolean models in information retrieval. In: Croft & Rijsbergen (1994): SIGIR 1994, S. 182–190.
- Paice, C.P.: Soft evaluation of boolean search queries in information retrieval systems. In: Information Technology: Research and Development, 3 (1), 1984, S. 33–42.
- Radecki, T.: Fuzzy set theoretical approach to document retrieval. In: Information Processing and Management, 15, 1979, S. 247–259.
- Sachs, W.M.: An approach to associative retrieval through the theory of fuzzy sets. In: Journal of the American Society for Information Science, 27, 1976, S. 85–87.
- Salton, G.; Fox, E.A.; Wu, H.: Extended boolean information retrieval. In: Communication of the ACM, 26(11), 1983, S. 1022–1036.
- Smith, M.E.: Aspekts of the p-norm model of information retrieval: syntactic query generation, efficiency, and theoretical properties. PhD thesis, Cornell University, 1990.
- Waller, W.G.; Kraft, D.H.: A mathematical Model for weighted Boolean retrieval systems. In: Information Processing and Management, 15, 1979, S. 235–245.
