二項分布 確率質量関数
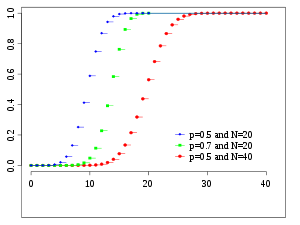
累積分布関数
色は上図と同じ
母数 n ≥ 0 {\displaystyle n\geq 0} 0 ≤ p ≤ 1 {\displaystyle 0\leq p\leq 1} 台 { 0 , … , n } {\displaystyle \{0,\dotsc ,n\}} 確率質量関数 ( n k ) p k ( 1 − p ) n − k {\displaystyle {\binom {n}{k}}p^{k}(1-p)^{n-k}} 累積分布関数 I 1 − p ( n − ⌊ k ⌋ , 1 + ⌊ k ⌋ ) {\displaystyle I_{1-p}{\bigl (}n-\lfloor k\rfloor ,1+\lfloor k\rfloor {\bigr )}} I ( − ) ( − , − ) {\displaystyle I_{(-)}(-,-)} 正則化不完全ベータ関数 ) 期待値 n p {\displaystyle np} 最頻値 { { ( n + 1 ) p − 1 , ( n + 1 ) p } ∩ { 0 , … , n } ( n + 1 ) p が 整 数 の 時 ⌊ ( n + 1 ) p ⌋ そ れ 以 外 {\displaystyle {\begin{cases}\{(n+1)p-1,(n+1)p\}\\\qquad \cap \{0,\dotsc ,n\}&(n+1)p{\text{が 整 数 の 時}}\\{\bigl \lfloor }(n+1)p{\bigr \rfloor }&{\text{そ れ 以 外}}\end{cases}}} 分散 n p ( 1 − p ) {\displaystyle np(1-p)} 歪度 1 − 2 p n p ( 1 − p ) {\displaystyle {\frac {1-2p}{\sqrt {np(1-p)}}}} 尖度 1 − 6 p ( 1 − p ) n p ( 1 − p ) {\displaystyle {\frac {1-6p(1-p)}{np(1-p)}}} モーメント母関数 ( 1 − p + p e t ) n {\displaystyle (1-p+p\,e^{t})^{n}} 特性関数 ( 1 − p + p e i t ) n {\displaystyle (1-p+p\,e^{it})^{n}} テンプレートを表示
数学 において、二項分布 (にこうぶんぷ、英 : binomial distribution )は、成功確率 p で成功か失敗のいずれかの結果となる試行(ベルヌーイ試行 と呼ばれる)を独立に n 回行ったときの成功回数を確率変数X とする離散確率分布 である。
二項分布に基づく統計的有意性 の検定は、二項検定 と呼ばれている。
例 二項分布の典型例を次に示す。全住民の5%がある感染症に罹患しており、その全住民の中から無作為に500人を抽出する。ただし住民は500人よりずっと多いとする。このとき、抽出された集団の中に罹患者が30人以上いる確率はどれくらいだろうか。
500人のうちの感染症患者の分布は、大抵の場合は全住民のうちの患者の分布(真の分布)とおおよそ似通っていると考えられる。しかし、低確率ではあるが、選んだ500人の中に1人も患者が含まれないような真の分布とかけ離れた分布が得られる場合もある。直観的には、真の分布に近い分布が得られる確率は、真の分布から遠い分布が得られる確率より大きい。たとえば、500人中の患者の数が500×0.05=25人である確率は、24人や26人である確率より大きいだろうと思われる。しかし、その確率は定量的にどれほどだろうか。 これを定量的に表すことのできる分布が二項分布である。
抽出された集団の中に含まれる罹患者数を確率変数 X で表すとき、X は n = 500p = 0.05Pr[X ≥ 30] である。
定義 単純な定義としては、成功確率p の試行を独立にn 回行い、成功回数を横軸にとってヒストグラムを作成した時のグラフの形である。このグラフの関数は下記の性質を持つ。
2つの母数 p (0 ≤ p ≤ 1 となる実数), n (自然数)に対して、0 以上の整数を値としてとる確率変数X を定める。このとき、X は試行の成功回数なので、(0 ≤ X ≤ n ) である。
そして、X = x 確率質量関数 )fX (x )
f X ( x ) = ( n x ) p x ( 1 − p ) n − x {\displaystyle f_{X}(x)={\binom {n}{x}}p^{x}(1-p)^{n-x}} となることが性質よりわかる。
また、fX (x )
∑ x = 0 n f X ( x ) = 1 {\displaystyle \sum _{x=0}^{n}f_{X}(x)=1} も明らかである。
上記を定義として、x をk に書き換え、
f X ( k ) = P ( X = k ) = ( n k ) p k ( 1 − p ) n − k {\displaystyle f_{X}(k)=P(X=k)={\binom {n}{k}}p^{k}(1-p)^{n-k}} で与えられるとき、X は二項分布B(n , p ) に従う、という。これはX ∼ B(n , p )
ここで、
( n k ) = n C k = n ! k ! ( n − k ) ! {\displaystyle {\binom {n}{k}}={}_{n}\!\mathrm {C} _{k}={\frac {n!}{k!\,(n-k)!}}} は n 個から k 個を選ぶ組合せの数、すなわち二項係数 を表す。二項分布という名前は、この二項係数に由来している。
n = 1ベルヌーイ分布 と呼ぶ。
上の定義式は次のように解釈することができる。1回の試行において成功する確率が p であるとき、pk は k 回成功する確率を表し、(1 − p )n −k は n − k k 回の成功は n 回の試行の中のどこかで発生したものであるから、n k n 回の独立な試行を行ったときの成功回数が k となる確率を求めることができる。
性質の導出 期待値・分散 二項分布 B(n , p ) に従う確率変数 X に対し、X の期待値 E [X ]
E [ X ] = ∑ k = 0 n k f X ( k ) = ∑ k = 0 n k ( n k ) p k ( 1 − p ) n − k = ∑ k = 1 n k ( n k ) p k ( 1 − p ) n − k = ∑ k = 1 n k n ! ( n − k ) ! k ! p k ( 1 − p ) n − k = ∑ k = 1 n n ! ( n − k ) ! ( k − 1 ) ! p k ( 1 − p ) n − k = ∑ k = 1 n n ( n − 1 ) ! ( n − k ) ! ( k − 1 ) ! p p k − 1 ( 1 − p ) n − k = n p ∑ k = 1 n ( n − 1 ) ! ( n − k ) ! ( k − 1 ) ! p k − 1 ( 1 − p ) n − k {\displaystyle {\begin{aligned}E[X]&=\sum _{k=0}^{n}kf_{X}(k)\\&=\sum _{k=0}^{n}k{\binom {n}{k}}p^{k}(1-p)^{n-k}\\&=\sum _{k=1}^{n}k{\binom {n}{k}}p^{k}(1-p)^{n-k}\\&=\sum _{k=1}^{n}k{\frac {n!}{(n-k)!\,k!}}p^{k}(1-p)^{n-k}\\&=\sum _{k=1}^{n}{\frac {n!}{(n-k)!\,(k-1)!}}p^{k}(1-p)^{n-k}\\&=\sum _{k=1}^{n}n{\frac {(n-1)!}{(n-k)!\,(k-1)!}}pp^{k-1}(1-p)^{n-k}\\&=np\sum _{k=1}^{n}{\frac {(n-1)!}{(n-k)!\,(k-1)!}}p^{k-1}(1-p)^{n-k}\\\end{aligned}}} ここで、k ′ = k − 1
= n p ∑ k = 1 n ( n − 1 ) ! ( n − k ) ! ( k − 1 ) ! p k − 1 ( 1 − p ) n − k = n p ∑ k ′ = 0 n − 1 ( n − 1 ) ! ( ( n − 1 ) − k ′ ) ! k ′ ! p k ′ ( 1 − p ) ( n − 1 ) − k ′ = n p ∑ k ′ = 0 n − 1 ( n − 1 k ′ ) p k ′ ( 1 − p ) ( n − 1 ) − k ′ = n p {\displaystyle {\begin{aligned}&{\hphantom {=}}np\sum _{k=1}^{n}{\frac {(n-1)!}{(n-k)!\,(k-1)!}}p^{k-1}(1-p)^{n-k}\\&=np\sum _{k'=0}^{n-1}{\frac {(n-1)!}{{\bigl (}(n-1)-k'{\bigr )}!\,k'!}}p^{k'}(1-p)^{(n-1)-k'}\\&=np\sum _{k'=0}^{n-1}{\binom {n-1}{k'}}p^{k'}(1-p)^{(n-1)-k'}\\&=np\\\end{aligned}}} これは全ての順序付けられた試行パターンについての平均値でもある。
続いて、分散 V [X ]
V [ X ] = E [ X 2 ] − ( E [ X ] ) 2 {\displaystyle V[X]=E{\bigl [}X^{2}{\bigr ]}-{\bigl (}E[X]{\bigr )}^{2}} 上と同様に
E [ X 2 ] = ∑ k = 0 n k 2 P ( X = k ) = ∑ k = 1 n k ( k − 1 ) ( n k ) p k ( 1 − p ) n − k + ∑ k = 1 n k ( n k ) p k ( 1 − p ) n − k = ∑ k = 1 n n ! ( n − k ) ! ( k − 2 ) ! p k ( 1 − p ) n − k + E [ X ] = ∑ k = 2 n n ! ( n − k ) ! ( k − 2 ) ! p k ( 1 − p ) n − k + n p = n ( n − 1 ) p 2 ∑ k = 2 n ( n − 2 ) ! ( n − k ) ! ( k − 2 ) ! p k − 2 ( 1 − p ) n − k + n p = n ( n − 1 ) p 2 ∑ k ′ = 0 n − 2 ( n − 2 ) ! ( n − 2 − k ′ ) ! k ′ ! p k ′ ( 1 − p ) n − 2 − k ′ + n p = n ( n − 1 ) p 2 + n p {\displaystyle {\begin{aligned}E{\bigl [}X^{2}{\bigr ]}&=\sum _{k=0}^{n}k^{2}P(X=k)\\&=\sum _{k=1}^{n}k(k-1){\binom {n}{k}}p^{k}(1-p)^{n-k}+\sum _{k=1}^{n}k{\binom {n}{k}}p^{k}(1-p)^{n-k}\\&=\sum _{k=1}^{n}{\frac {n!}{(n-k)!\,(k-2)!}}p^{k}(1-p)^{n-k}+E[X]\\&=\sum _{k=2}^{n}{\frac {n!}{(n-k)!\,(k-2)!}}p^{k}(1-p)^{n-k}+np\\&=n(n-1)p^{2}\sum _{k=2}^{n}{\frac {(n-2)!}{(n-k)!\,(k-2)!}}p^{k-2}(1-p)^{n-k}+np\\&=n(n-1)p^{2}\sum _{k'=0}^{n-2}{\frac {(n-2)!}{(n-2-k')!\,k'!}}p^{k'}(1-p)^{n-2-k'}+np\\&=n(n-1)p^{2}+np\\\end{aligned}}} 合計して、
V [ X ] = n ( n − 1 ) p 2 + n p − n 2 p 2 = n p ( 1 − p ) {\displaystyle {\begin{aligned}V[X]&=n(n-1)p^{2}+np-n^{2}p^{2}\\&=np(1-p)\\\end{aligned}}} となる。
モーメント 二項分布 B(n , p ) に従う確率変数 X の r 次モーメント E [X r
E [ X r ] = ∑ j = 0 r S ( r , j ) n ! ( n − j ) ! p j {\displaystyle E{\bigl [}X^{r}{\bigr ]}=\sum _{j=0}^{r}S(r,j){\frac {n!}{(n-j)!}}p^{j}} というやや複雑な表示をもつ。ここで S (r , j )第二種スターリング数 。低次から
E [ X 1 ] = n p , E [ X 2 ] = n p + n ( n − 1 ) p 2 , … {\displaystyle E{\bigl [}X^{1}{\bigr ]}=np,\quad E[X^{2}]=np+n(n-1)p^{2},\dotsc } となる。一方 X の r 次階乗モーメント(英語版) E [(X )r
E [ ( X ) r ] = ( n ) r p r = n ! ( n − r ) ! p r {\displaystyle E{\bigl [}(X)_{r}{\bigr ]}=(n)_{r}p^{r}={\frac {n!}{(n-r)!}}p^{r}} という単純な表示をもつ。ここで (n )r n !/(n − r )! はポッホハマー記号 。低次から
E [ ( X ) 1 ] = n p , E [ ( X ) 2 ] = n ( n − 1 ) p 2 , … {\displaystyle E{\bigl [}(X)_{1}{\bigr ]}=np,\quad E{\bigl [}(X)_{2}{\bigr ]}=n(n-1)p^{2},\dotsc } となる。
再生性 二項分布は再生性 を有する。すなわち B(n , p ) に従う確率変数 X と B(m , p ) に従う確率変数 Y が互いに独立であるとき、確率変数の和 X + Y B(n + m , p ) に従う。
近似 二項分布の近似 として、以下の小節に挙げる分布 などが知られている。 近似を用いることで計算の労力を削減できるという利点がある一方、各近似にはそれを適用可能とするための条件が存在する。 そのため、それらの条件や近似を用いることで生じる誤差が許容可能な範囲内に収まっていることの確認が必要となる。 特に、二項分布の母比率の信頼区間 を求める際には、用いる近似と変数の値の組み合わせにより、厳密に求められた信頼区間との間に近似誤差が生じることになるため注意が必要である[5]
正規分布 二項分布が正規分布に近づく様子 期待値 np および分散 np (1 − p )5 よりも大きい場合、二項分布 B(n , p ) に対する良好な近似として正規分布 がある。ただし、この近似を適用するにあたっては、変数のスケールに注意し、連続な分布への適切な処理がなされる必要がある。より厳密に述べれば、n が十分大きくかつ、期待値 np および 分散 np (1 − p )np , 分散 np (1 − p )N(np , np (1 − p )) で近似することができ、期待値からの差 |k − np | が標準偏差 n p ( 1 − p ) {\textstyle {\sqrt {np(1-p)}}} k に対して
P [ X = k ] ≃ 1 2 π n p ( 1 − p ) exp ( − ( k − n p ) 2 2 n p ( 1 − p ) ) {\displaystyle P[X=k]\simeq {\frac {1}{\sqrt {2\pi np(1-p)}}}\exp {\biggl (}-{\frac {(k-np)^{2}}{2np(1-p)}}{\biggr )}} が漸近的に成り立つ。二項分布が一定の条件下で正規分布に近づく、この近似式は数学者アブラーム・ド・モアブル が1733年に著書 The Doctrine of Chances ド・モアブル=ラプラスの極限定理 またはラプラスの定理と呼ぶことがある[6] 中心極限定理 の特別な場合に相当する。この正規分布への近似と標準正規分布表により、計算の労力を大きく削減することができる。
例えば、多数の住民の中から n 人を無作為に抽出し、ある質問について同意するかどうかを尋ねる場合を考える。同意する人数の割合は、もちろんサンプルに依存する。n 人を無作為に抽出する作業を何度も繰り返し行うとき、同意する人々の割合の分布は、実際の全住民の合意割合 p とほぼ等しい平均 を持ち、標準偏差 σ = p ( 1 − p ) / n {\textstyle \sigma ={\sqrt {p(1-p)/n}}} p は、標準偏差が小さいほど正確な推定が可能である。そのため、抽出する人数 n は多い方が好ましい。
95%信頼区間 ならば、正規分布で近似すると、その範囲は
p − 1.959964 p ( 1 − p ) n ∼ p + 1.959964 p ( 1 − p ) n {\displaystyle p-1.959964{\sqrt {\frac {p(1-p)}{n}}}\sim p+1.959964{\sqrt {\frac {p(1-p)}{n}}}} となる。たとえば、p = 50%n = 10040%–60% 、n = 100047%–53% 、n = 1000049%–51% となる。n = 1089% 信頼区間で、30%–70% となる[7]
ポアソン分布 n が大きく p が十分小さい場合、np は適度な大きさとなるため、λ = np ポアソン分布 が二項分布 B(n , p ) の良好な近似を与える。すなわち、n が十分大きいとき、期待値 λ = np
P [ X = k ] ≃ λ k e − λ k ! {\displaystyle P[X=k]\simeq {\frac {\lambda ^{k}e^{-\lambda }}{k!}}} が成り立つ(詳細はポアソン分布 の項を参照)。この結果は数学者シメオン・ドニ・ポアソン が1837年に著書 Recherches sur la probabilite des jugements (Researches on the Probabilities ) の中で与えており、ポアソンの極限定理 と呼ばれる。
出典 [脚注の使い方 ]
^ "EBCIC: Exact Binomial Confidence Interval Calculator" https://kazkobara.github.io/ebcic/README-jp.html ^ 伏見康治 「確率論及統計論」第IV章 独立偶然量の和 27節 Bernoulliの定理, Laplaceの定理 p.452 ISBN 9784874720127 http://ebsa.ism.ac.jp/ebooks/ebook/204^ prob 3 <= x <= 7 for x binomial with n=10 and p=0.5 — Wolfram Alpha 参考文献 藪友良 『入門実践する統計学』東洋経済新報社、2012年。ISBN 978-4-492-47085-5。https://books.google.com/books?id=EJWJ86L2bK4C 。 Johnson, N. L.; Kotz, A. W.; Kemp, S. (2005). Univariate Discrete Distributions (Third ed.). Wiley. ISBN 0-471-27246-9. MR 2163227. Zbl 1092.62010 関連項目 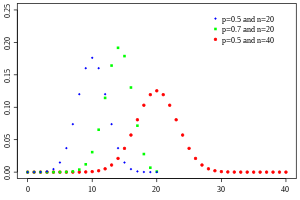

















![{\displaystyle {\begin{aligned}E[X]&=\sum _{k=0}^{n}kf_{X}(k)\\&=\sum _{k=0}^{n}k{\binom {n}{k}}p^{k}(1-p)^{n-k}\\&=\sum _{k=1}^{n}k{\binom {n}{k}}p^{k}(1-p)^{n-k}\\&=\sum _{k=1}^{n}k{\frac {n!}{(n-k)!\,k!}}p^{k}(1-p)^{n-k}\\&=\sum _{k=1}^{n}{\frac {n!}{(n-k)!\,(k-1)!}}p^{k}(1-p)^{n-k}\\&=\sum _{k=1}^{n}n{\frac {(n-1)!}{(n-k)!\,(k-1)!}}pp^{k-1}(1-p)^{n-k}\\&=np\sum _{k=1}^{n}{\frac {(n-1)!}{(n-k)!\,(k-1)!}}p^{k-1}(1-p)^{n-k}\\\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1e62030d0bd61766c82b8cc3579b43685b48665c)

![{\displaystyle V[X]=E{\bigl [}X^{2}{\bigr ]}-{\bigl (}E[X]{\bigr )}^{2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1792ce6af03f6fbe17ad439bfdc19a00ece8eb8c)
![{\displaystyle {\begin{aligned}E{\bigl [}X^{2}{\bigr ]}&=\sum _{k=0}^{n}k^{2}P(X=k)\\&=\sum _{k=1}^{n}k(k-1){\binom {n}{k}}p^{k}(1-p)^{n-k}+\sum _{k=1}^{n}k{\binom {n}{k}}p^{k}(1-p)^{n-k}\\&=\sum _{k=1}^{n}{\frac {n!}{(n-k)!\,(k-2)!}}p^{k}(1-p)^{n-k}+E[X]\\&=\sum _{k=2}^{n}{\frac {n!}{(n-k)!\,(k-2)!}}p^{k}(1-p)^{n-k}+np\\&=n(n-1)p^{2}\sum _{k=2}^{n}{\frac {(n-2)!}{(n-k)!\,(k-2)!}}p^{k-2}(1-p)^{n-k}+np\\&=n(n-1)p^{2}\sum _{k'=0}^{n-2}{\frac {(n-2)!}{(n-2-k')!\,k'!}}p^{k'}(1-p)^{n-2-k'}+np\\&=n(n-1)p^{2}+np\\\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f36a3add5dd457bf590647d74ad2a07db97b7ddb)
![{\displaystyle {\begin{aligned}V[X]&=n(n-1)p^{2}+np-n^{2}p^{2}\\&=np(1-p)\\\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d7f5b914785579ba9e46c48af50a3f13852f09f4)
![{\displaystyle E{\bigl [}X^{r}{\bigr ]}=\sum _{j=0}^{r}S(r,j){\frac {n!}{(n-j)!}}p^{j}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e5b777835981df6c24f03794aaeb155e9f60a050)
![{\displaystyle E{\bigl [}X^{1}{\bigr ]}=np,\quad E[X^{2}]=np+n(n-1)p^{2},\dotsc }](https://wikimedia.org/api/rest_v1/media/math/render/svg/e73605e42e6ed402fd542af6a3bccc368e3919cb)
![{\displaystyle E{\bigl [}(X)_{r}{\bigr ]}=(n)_{r}p^{r}={\frac {n!}{(n-r)!}}p^{r}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8dd2e13e6b0607a1268f28eea4979c49ff5c7ce9)
![{\displaystyle E{\bigl [}(X)_{1}{\bigr ]}=np,\quad E{\bigl [}(X)_{2}{\bigr ]}=n(n-1)p^{2},\dotsc }](https://wikimedia.org/api/rest_v1/media/math/render/svg/66606bd9610727d3043bab19139b806118049a28)


![{\displaystyle P[X=k]\simeq {\frac {1}{\sqrt {2\pi np(1-p)}}}\exp {\biggl (}-{\frac {(k-np)^{2}}{2np(1-p)}}{\biggr )}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/68c3475a5cdc5931f3a90d35890dced7900c1361)


![{\displaystyle P[X=k]\simeq {\frac {\lambda ^{k}e^{-\lambda }}{k!}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/233a7e3df1346cfbaeac71c279bbf8d22a6d66b7)





